In Part 1, we explored the theoretical foundations of RAG systems. Now, let’s build a working implementation! We’ll create a RAG system that answers questions about recent Wikipedia articles, showing how LLMs can work with fresh data.
1. System Architecture
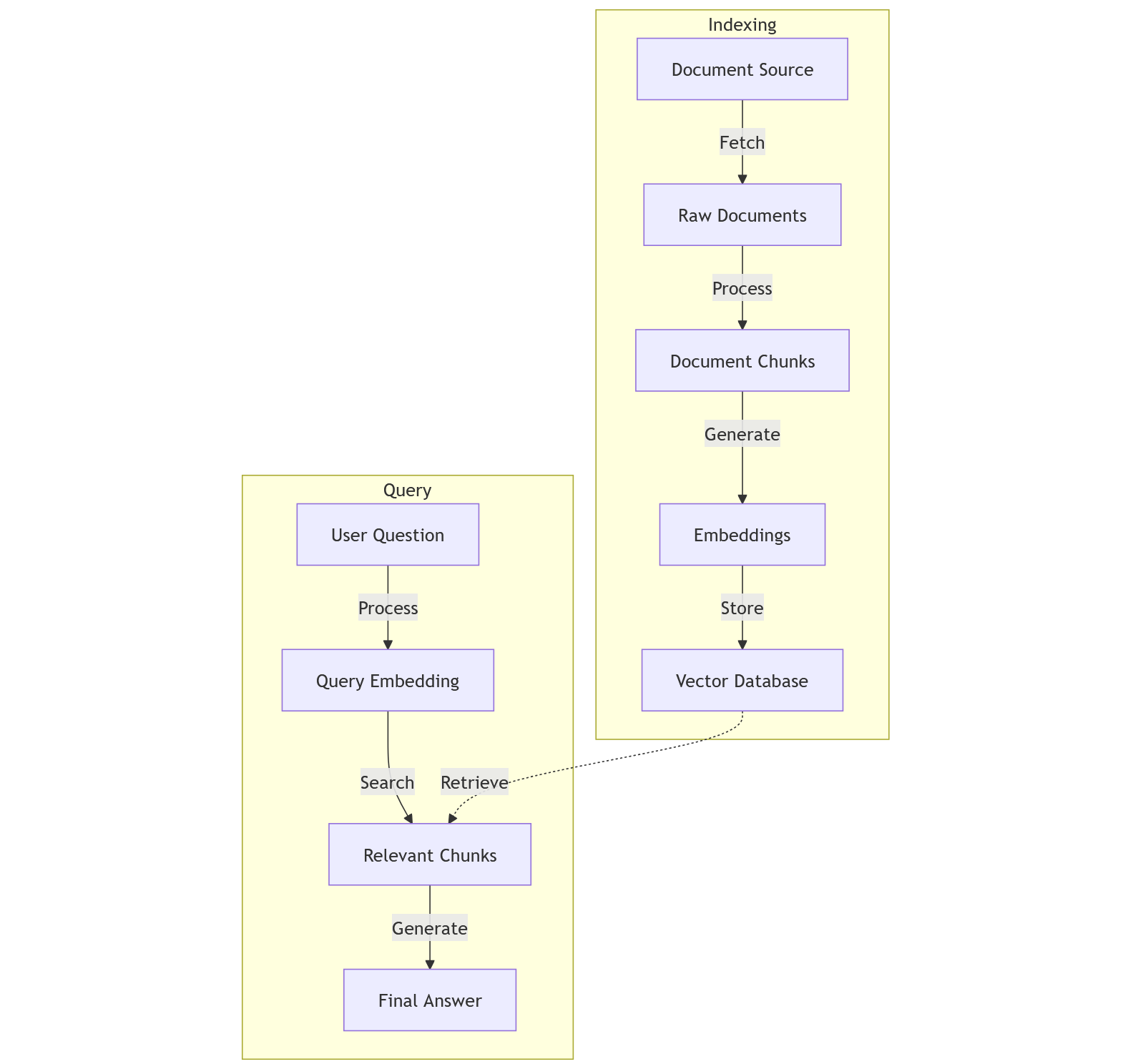
A RAG system operates in two distinct phases: indexing and querying. Understanding these phases is crucial for both development and production deployment.
1. Indexing Phase
The indexing phase prepares your documents for efficient retrieval. During this phase, the system:
Fetches and processes documents from your data sources
Splits them into optimal chunks for context retention
Generates vector embeddings for semantic understanding
Stores them in a vector database for quick access
In production environments, this phase typically runs as a background process. You might schedule it to run on a fixed schedule or trigger it when source documents update. This ensures your knowledge base remains current without impacting real-time query performance.
2. Query Phase
The query phase handles real-time user interactions. When a query comes in:
The system processes the user’s question
Retrieves the most semantically relevant chunks
Uses an LLM to generate a coherent response
This process happens in real-time as part of your application’s request-response cycle, typically completing within seconds.
2. Building the Indexing Pipeline
2.1 Project Setup
We’ll use Next.js as our application framework and LangChain as our RAG toolkit. This combination provides a robust foundation for building production-ready RAG systems.
Proper environment configuration is essential for development and production environments. We need to manage API keys and other sensitive configuration securely.
Terminal window
npminstalldotenv
Create your environment files:
Terminal window
# .env (for development)
OPENAI_API_KEY=your_api_key_here
# .env.local (for Next.js)
OPENAI_API_KEY=your_api_key_here
Important: These files contain sensitive credentials. Add them to your .gitignore to prevent accidental commits.
For scripts outside Next.js, import the environment configuration:
import'dotenv/config';
2.2 Getting Our Data
We’re using Wikipedia as our data source for several practical reasons:
The API provides clean, structured content
Articles are regularly updated
Content is well-formatted and requires minimal preprocessing
Perfect for demonstrating how RAG handles current events
Let’s create a simple script to fetch and prepare data from Wikipedia. This is a great example of how RAG systems can work with current information that exists outside of the LLM’s training cutoff date. Create a new file scripts/fetch-articles.js:
import { writeFileSync } from'fs';
asyncfunctionfetchArticles() {
// Wikipedia API endpoint for full article content
// Extract the page content (need to get the first page from pages object)
constpageId=Object.keys(data.query.pages)[0];
constarticle= {
title: data.query.pages[pageId].title,
content: data.query.pages[pageId].extract
};
// Save to file
writeFileSync(
'./data/article-1.txt',
`${article.title}\n\n${article.content}`
);
console.log('Article saved successfully');
} catch (error) {
console.error('Error fetching article:', error);
}
}
fetchArticles();
Create a data directory and run the script:
Terminal window
mkdirdata
nodescripts/fetch-articles.js
Output:
Article saved successfully
Important: Since we’re using ES modules outside of Next.js, add "type": "module" to your package.json file:
{
"name": "rag-tutorial",
"type": "module",
...
}
Why Wikipedia?
While we could fetch data from various news sources, Wikipedia offers several advantages for this tutorial:
Reliable API: Wikipedia provides a stable, well-documented API that’s easy to work with
Structured Data: The content is already well-formatted and cleaned
Current Events: Wikipedia pages are regularly updated with recent information
Educational Purpose: Using Donald Trump’s page as an example helps demonstrate how RAG systems can provide information about recent events that occurred after the LLM’s training cutoff date
2.3 Document Processing
The document processing step is critical for retrieval quality. We implement intelligent chunking that:
Maintains semantic coherence with 1000-token chunks
Preserves context through 200-token overlaps
Retains metadata for traceability
Uses natural break points like paragraphs
First, let’s create a robust document loader that handles chunking and metadata. Create lib/document-loader.js:
"What are Donald Trump's most recent political activities?",
"What legal challenges is Trump currently facing?",
"Who won and who as the runner up in the 2024 Republican primaries?"
];
console.log('Testing RAG system with sample queries...\n');
for (constquestionofquestions) {
console.log(`Question: ${question}`);
console.log('Thinking...');
conststartTime=Date.now();
constanswer=awaitqueryDocuments(question);
constduration=Date.now() -startTime;
console.log('\nAnswer:', answer);
console.log(`Duration: ${duration}ms\n`);
console.log('-'.repeat(50), '\n');
}
}
testQueries().catch(console.error);
Run the tests:
Terminal window
nodescripts/test-queries.js
Example output:
Testing RAG system with sample queries...
Question: What are Donald Trump's most recent political activities?
Thinking...
Split into 165 chunks
Answer: {
answer: 'In the 2022 midterm elections, Donald Trump endorsed over 200 candidates for various offices, most of whom supported his false claim that the 2020 presidential election was stolen from him. He continued fundraising, raised more than twice as much as the Republican Party itself, and focused on how elections are run and on ousting election officials who had resisted his attempts to overturn the 2020 election results.',
Question: What legal challenges is Trump currently facing?
Thinking...
Answer: {
answer: 'Trump is currently facing a civil fraud case filed by the attorney general of New York, in which he was found liable, ordered to pay a penalty of over $450 million, and barred from serving as an officer or director of any New York corporation or legal entity for three years. Additionally, he is facing federal charges related to national defense information under the Espionage Act, making false statements, conspiracy to obstruct justice, and other charges.',
if (error.message.includes('rate limit') &&i<retries-1) {
awaitwait(Math.pow(2, i) *1000);
continue;
}
throwerror;
}
}
};
2. Vector Store Persistence
If you see Error: Vector store not initialized, check:
Directory permissions
File corruption in the ./data directory
Sufficient disk space
3. Large Documents
For maximum context length errors:
Reduce chunk size (try 500 tokens)
Decrease chunk overlap
Use more selective retrieval
4. Memory Issues
If processing large articles:
Process documents in batches
Implement streaming for large files
Monitor memory usage during embedding generation
6. Conclusion
This tutorial got you started with a working RAG system that can process Wikipedia articles and answer questions about them. You can now experiment with this implementation:
Try different chunk sizes and overlap settings
Test with other Wikipedia articles
Modify the prompt templates
Add more error handling cases
Get Your Free Developer Guide
🎁 Production-ready guides, checklists, and code examples
Join 1,000+ developers getting practical guides on Next.js, Stripe, AI, and more.
Copy-paste code examples you can use immediately
Production-ready checklists to avoid common mistakes